Image Sculpting: Precise Object Editing with 3D Geometry Control
CVPR 2024

Pose Editing

Input Image
3D Geometry
Edited Geometry

Edited Image

Input Image
3D Geometry
Edited Geometry

Edited Image

Input Image
3D Geometry
Edited Geometry

Edited Image

Input Image
3D Geometry
Edited Geometry

Edited Image

Input Image
3D Geometry
Edited Geometry

Edited Image
Input Image
3D Geometry
Edited Geometry

Edited Image

Input Image
3D Geometry
Edited Geometry

Edited Image
We present Image Sculpting, a new framework for editing 2D images by incorporating tools from 3D geometry and graphics. This approach differs markedly from existing methods, which are confined to 2D spaces and typically rely on textual instructions, leading to ambiguity and limited control. Image Sculpting converts 2D objects into 3D, enabling direct interaction with their 3D geometry. Post-editing, these objects are re-rendered into 2D, merging into the original image to produce high-fidelity results through a coarse-to-fine enhancement process. The framework supports precise, quantifiable, and physically-plausible editing options such as pose editing, rotation, translation, 3D composition, carving, and serial addition. It marks an initial step towards combining the creative freedom of generative models with the precision of graphics pipelines.
Our proposed Image Sculpting framework, which metaphorically suggests the flexible and precise sculpting of a 2D image in a 3D space, integrates three key components: (1) single-view 3D reconstruction , (2) manipulation of objects in 3D , and (3) a coarse-to-fine generative enhancement process . More specifically, 2D objects are converted into 3D models, granting users the ability to interact with and manipulate the 3D geometry directly, which allows for precision in editing. The manipulated objects are then seamlessly reincorporated into their original or novel 2D contexts, maintaining visual coherence and fidelity.
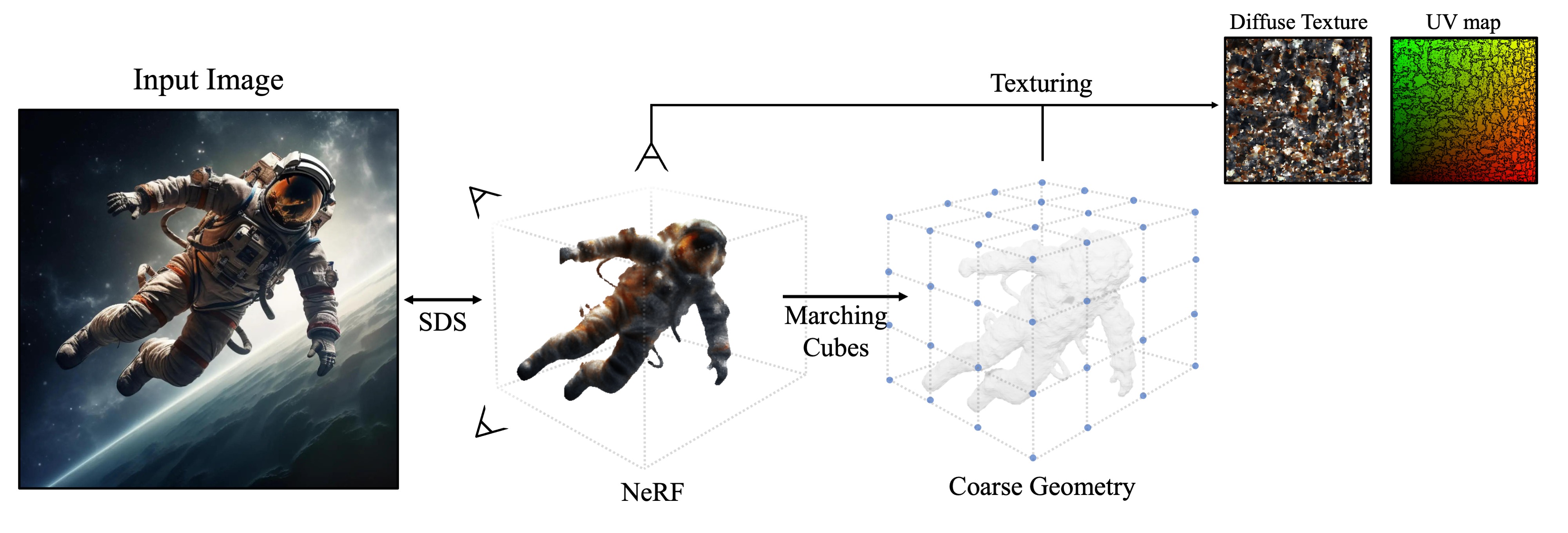
Given an image of an object, our goal is to perform 3D reconstruction to obtain its 3D model.
Image to 3D model
Our initial step involves segmenting the selected object from the input image
using SAM
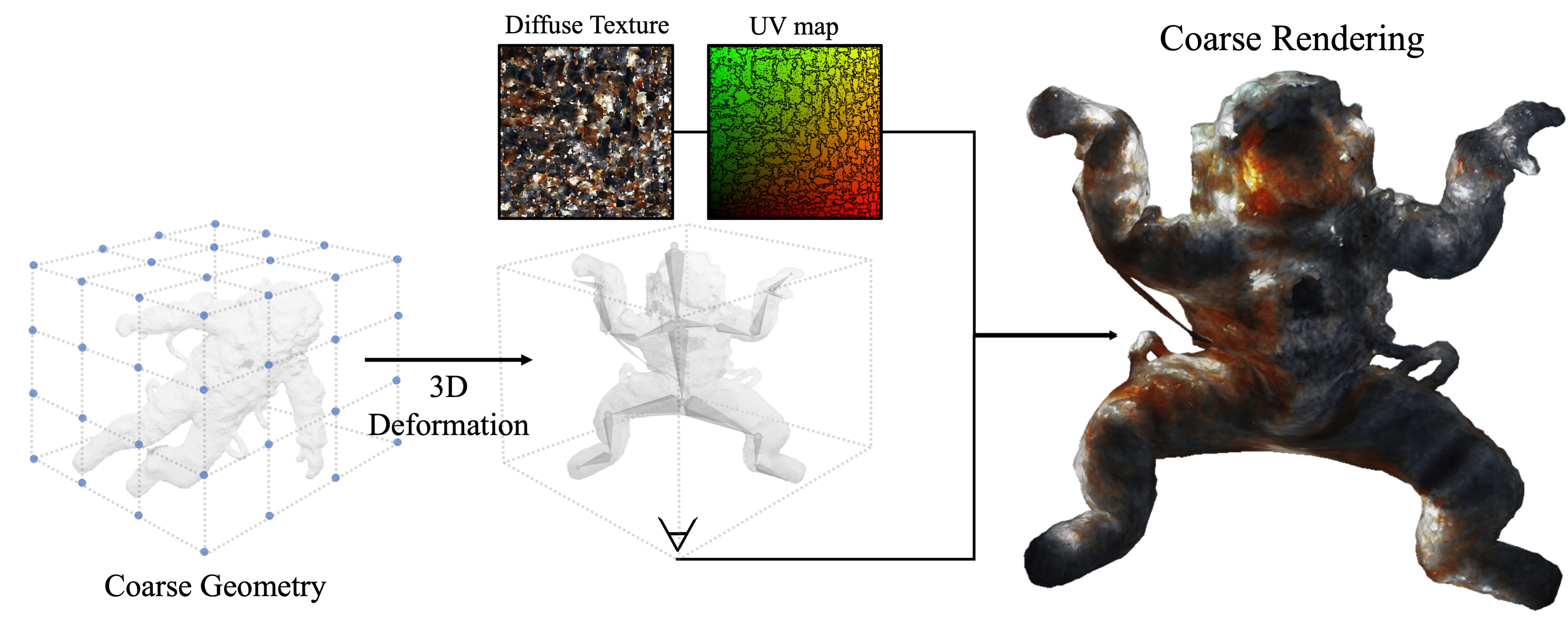
After obtaining the 3D model, a user can manually construct a skeleton and interactively manipulate it by rotating the bones to achieve the target pose. The mesh deformation affects the vertex positions of the object but not the UV coordinates used for texture mapping; this procedure thus deforms the texture mapped on the object following its deformation.
However, the resulting image quality depends on the 3D reconstruction's accuracy, which, in our case, is coarse and insufficient for the intended visual outcome. Therefore, we rely on an image enhancement pipeline to convert the coarse rendering into a high-quality output.
This section focuses on blending a coarsely rendered image back to its original background.
The aim is to restore textural details while keeping the edited geometry intact.
Image restoration and enhancement are commonly approached as image-to-image translation tasks
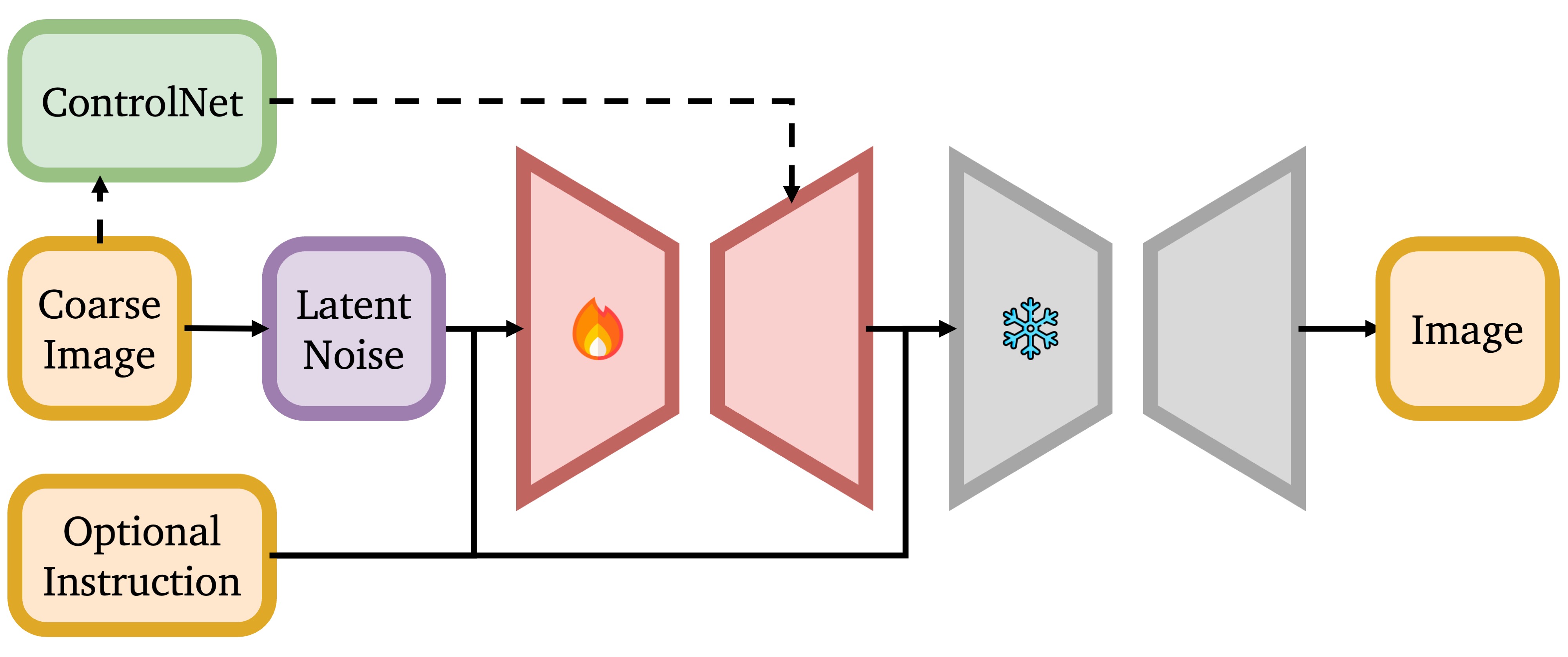
To address the balance between preserving texture and geometry,
our approach begins by "personalizing" a pre-trained text-to-image
diffusion model. To capture the object's key features,
we fine-tune the diffusion model with DreamBooth
One-shot Dreambooth
DreamBooth
Depth Control
We use depth ControlNet
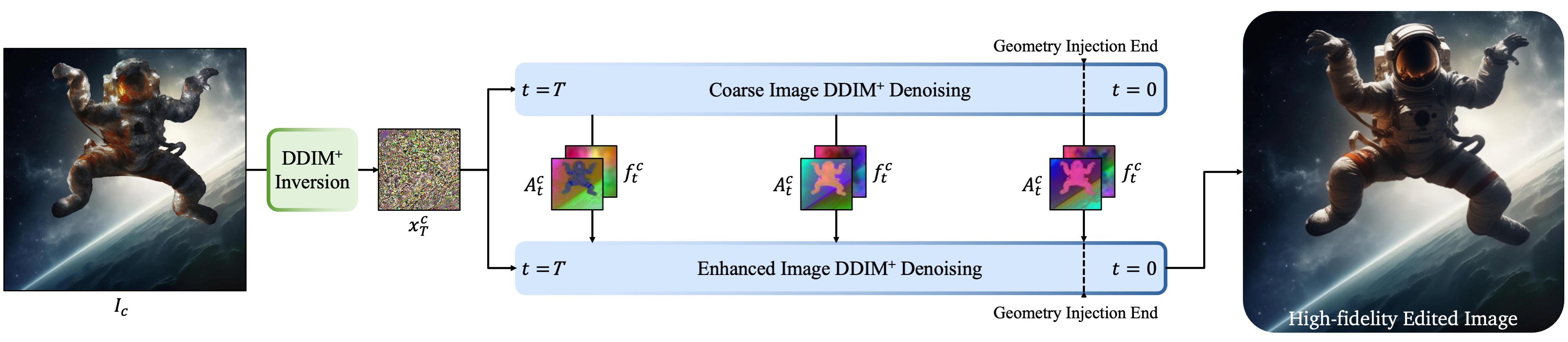
Feature Injection
To better preserve the geometry, we use feature injection.
This step begins with DDIM inversion
Our approach introduces new editing features through precise 3D geometry control, a capability not present in existing methods. We compare our method with the state-of-the-art object editing techniques for a comprehensive analysis.

In this figure, we show that 3DIT
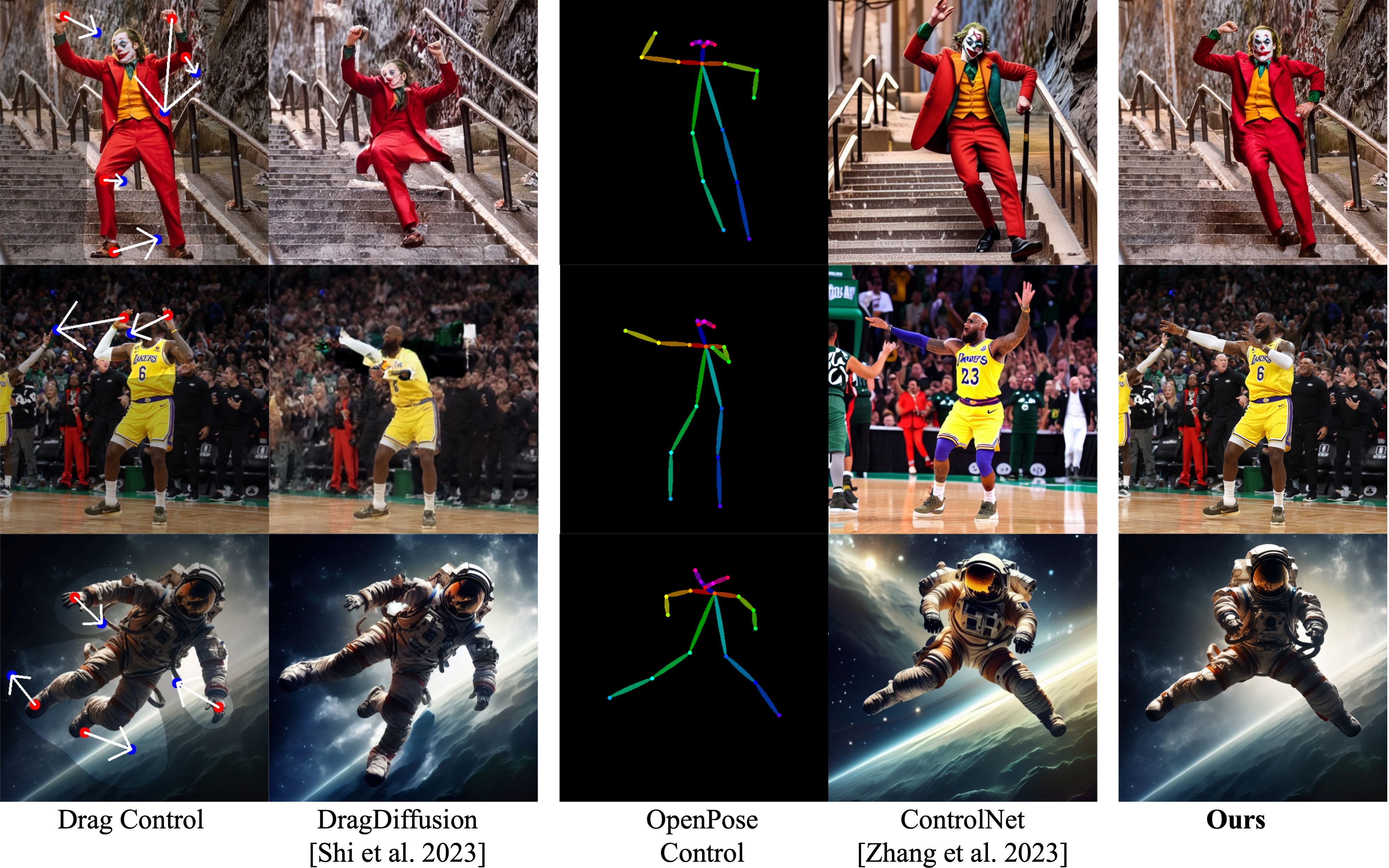
In this figure, we compare the pose editing ability with
DragDiffusion

Furthermore, we show how text-based editing methods like
InstructPix2Pix
@article{Image Sculpting,
title={Image Sculpting: Precise Object Editing with 3D Geometry Control},
author={Jiraphon Yenphraphai, Xichen Pan, Sainan Liu, Daniele Panozzo and Saining Xie},
year={2024},
journal={arXiv preprint arXiv:2401.01702},
}




































